「手順書を作って」から始まる問題
Dataikuを導入した企業の新規プロジェクトで、実装が現実的になった段階で、
「ユーザー向け手順書の作成をお願いします。」
という依頼を受けたことがある。
何が問題になったかというと、「誰向けの、何のための手順書か」が決まっていないことで、作成したものが使われずらいもので、修正依頼が多々来たことである。
Dataikuはノーコード分析からPythonベースのモデル開発、API Deployer、シナリオによるパイプライン自動化まで守備範囲が広い。ロールごとの利用シーンを片っ端から洗い出すと、手順書の数はどんどん増えていく。何も考えずに書き始めると、似たような内容のドキュメントが乱立し、作るのも更新するのも時間的コストがかかってしまう。
本稿では、実際のDataiku導入プロジェクトで行ったドキュメント設計のプロセスを共有する。ロールの定義、統合・分離の判断基準、dev/prod環境のライブラリ管理、そしてMLOpsサイクルとの対応関係まで、一通り整理してみた。
1. まず「誰がDataikuを使うのか」を決める
手順書を書き始める前に、利用者を分類する。我々のプロジェクトでは5つのロールを置いた。
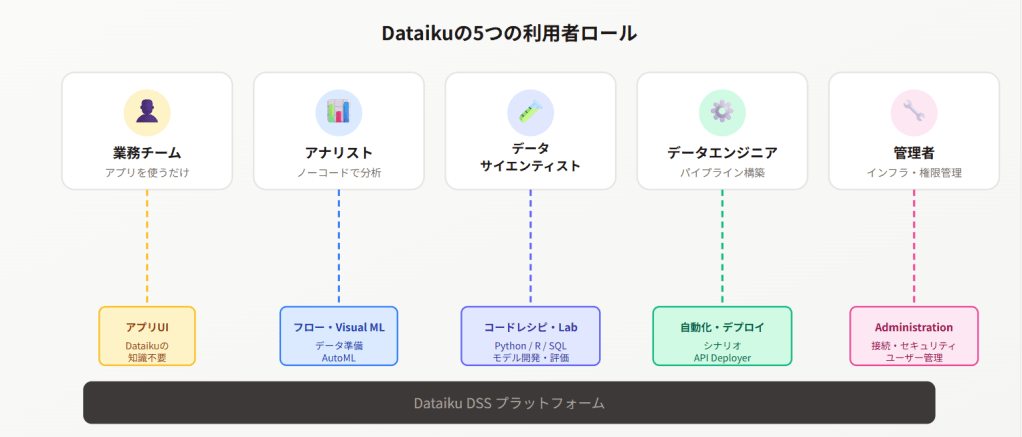
| ロール | 概要 | Dataikuの利用レイヤー |
|---|---|---|
| 業務チーム | Dataikuアプリのエンドユーザー。プラットフォームの知識はゼロ | アプリUI |
| アナリスト | ノーコードでデータ準備・Visual MLを活用 | フロー・Visual ML |
| データサイエンティスト | Python/R/SQLによるモデル開発・評価 | コードレシピ・Notebook・Lab |
| データエンジニア | パイプライン構築・シナリオ・API Deployer運用 | 自動化・デプロイ |
| 管理者 | インフラ・接続・権限管理 | Administration |
気をつけたいのが業務チームの扱いだ。彼らにとって「フロー」「レシピ」「シナリオ」は全部よくわからない単語でしかない。アプリを開いて、操作して、結果を見る。やることはそれだけだ。
だから、業務チーム向けのドキュメントにはDataikuという言葉を出さない。「分析ツール」「○○システム」など、業務の文脈に合った名前で統一する。地味な工夫だが、副次的な効果もある。将来プラットフォームを乗り換えることになっても、業務チーム側のドキュメント改修が少なくて済む。
2. 「まとめるもの」と「分けるもの」の線引き
ロールを決めたら、次は統合と分離の判断基準を定める。

まとめられるケース
操作の流れが共通で、変わるのがプロジェクト固有のパラメータだけなら、1本にまとめてよい。
たとえばフロー操作やレシピ作成の手順は、プロジェクトが変わってもやることは同じだ。違うのはデータセット名やモデル名、接続先くらい。であれば、こういう構成にする。
共通手順書(1本) + プロジェクト別パラメータシート(テンプレート)
プロジェクトが増えてもパラメータシートを埋めるだけで回せるので、複数プロジェクトを並行する現場ほど楽になる。
分けなければいけないケース
読む人と目的が違うドキュメントは、絶対に分ける。 わかりやすいのがアプリの「作成」と「利用」だ。
| ドキュメント | 対象者 | 目的 |
|---|---|---|
| アプリ利用マニュアル | 業務チーム | アプリを使う |
| アプリ作成手順(開発標準手順書に統合) | アナリスト・DS | アプリを作る |
読む人の技術レベルも関心も全然違う。一緒にすると、どちらにとっても読みにくいドキュメントになる。
3. dev/prod環境とPythonライブラリ管理
Dataikuを本番運用するなら、開発環境(dev)と本番環境(prod)の分離は前提になる。ここで見落とされがちなのがコードenv・Pythonライブラリの管理だ。
dev/prodそれぞれでコードenvを別々に管理する必要があり、これは複数のドキュメントにまたがる話になる。我々はこの部分を専用の手順書として独立させた。理由は以下の3つ。
- dev→prodへのライブラリ反映は、コードのデプロイとは別の手順がある
- prod環境への反映には承認フローが必要で、誰が承認するのかを書く場所がいる
- ライブラリの競合やバージョン不整合が起きたときの対処は、他の手順書と話の文脈が違う
後述するライフサイクルマッピングを見るとわかるが、この手順書は環境構築・開発・デプロイ・保守の4フェーズにまたがる。一番早く整備しておくべきドキュメントだった。
4. 手順書の最終構成
ここまでの方針で整理した結果、以下の構成になった。
共通手順書(9本)
| # | 手順書名 | 対象ロール | 主な内容 |
|---|---|---|---|
| B | FAQ・問い合わせガイド | 業務チーム | よくあるエラーと対処法 / エスカレーションフロー / 問い合わせ先 |
| D | モデル開発手順書 | アナリスト・DS | Visual ML / 学習・評価・チューニング / Python・R・SQLレシピ / プラグイン導入 |
| G | 環境構築・初期設定手順書 | 管理者 | DSSインストール / ライセンス適用 / データ接続設定 / dev・prod初期構築 |
| H | ユーザー・権限管理手順書 | 管理者 | ユーザーCRUD / グループ・ロール設定 / プロジェクト別権限 / dev・prod間の権限分離 |
| J | 保守・障害対応手順書 | 管理者・エンジニア | バックアップ・リストア / ログ解析 / バージョンアップ / 障害時エスカレーション |
| K | オンボーディング・引き継ぎガイド | 全ロール | 役割別の初期アクション / プロジェクト引き継ぎ / ドキュメント規約 / 手順書ガイドマップ |
| L | Dataiku 開発標準手順書 | アナリスト・DS | プロジェクト作成 / フロー設計・命名規約 / レシピ操作 / アプリ作成・公開 / ダッシュボード |
| M | Dataiku 運用標準手順書 | DS・エンジニア | API Deployer / Batchデプロイ / dev→prod昇格 / シナリオ構築 / モデル監視・ドリフト検知 |
| N | コードenv・Pythonライブラリ管理手順書 | 管理者・DS | dev・prodコードenv作成 / ライブラリ追加・バージョン管理 / dev→prod反映 / 承認フロー / 競合対処 |
プロジェクト固有手順書(アプリ数 × プロジェクト数分)
| # | 手順書名 | 対象ロール | 主な内容 |
|---|---|---|---|
| A | アプリ利用マニュアル | 業務チーム | アクセス・ログイン / 画面説明 / 入力・実行操作 / 結果確認 / CSV・Excel出力 |
プロジェクトごとに作成が必要なのは、このアプリ利用マニュアルだけだ。それ以外は共通手順書+パラメータシートでカバーできている。
テンプレート
| # | 名称 | 用途 | 主な内容 |
|---|---|---|---|
| T | プロジェクト別パラメータシート | L・M・Nと組み合わせて使用 | プロジェクト名・概要 / データセット一覧 / モデル名・バージョン / APIエンドポイント / スケジュール設定 / 使用ライブラリ(dev・prod別) / 担当者 |
5. ライフサイクルのどこで使うか
手順書は作っただけでは棚に置かれて終わる。どのフェーズで誰が開くのかをはっきりさせておかないと、現場で参照されない。
| # | 手順書名 | 環境構築 | 開発 | テスト | デプロイ | 運用 | 保守 |
|---|---|---|---|---|---|---|---|
| A | アプリ利用マニュアル | ✅ | |||||
| B | FAQ・問い合わせガイド | ✅ | |||||
| D | モデル開発手順書 | ✅ | ✅ | ||||
| G | 環境構築・初期設定手順書 | ✅ | |||||
| H | ユーザー・権限管理手順書 | ✅ | |||||
| J | 保守・障害対応手順書 | ✅ | |||||
| K | オンボーディング・引き継ぎガイド | ✅ | |||||
| L | Dataiku 開発標準手順書 | ✅ | ✅ | ||||
| M | Dataiku 運用標準手順書 | ✅ | ✅ | ||||
| N | コードenv・Pythonライブラリ管理手順書 | ✅ | ✅ | ✅ | ✅ | ||
| T | プロジェクト別パラメータシート | ✅ | ✅ | ✅ |
こうして並べると、何から手をつけるべきかが見える。N(コードenv管理)は4フェーズにまたがっているので、最初に書いておくと後が楽だ。T(パラメータシート)はテンプレートを早めに固めておくと、開発からデプロイへの引き継ぎで手戻りが減る。
6. MLOpsサイクルとの対応
ここまでの手順書構成は、そのままMLOps(Machine Learning Operations)の運用基盤として使える。
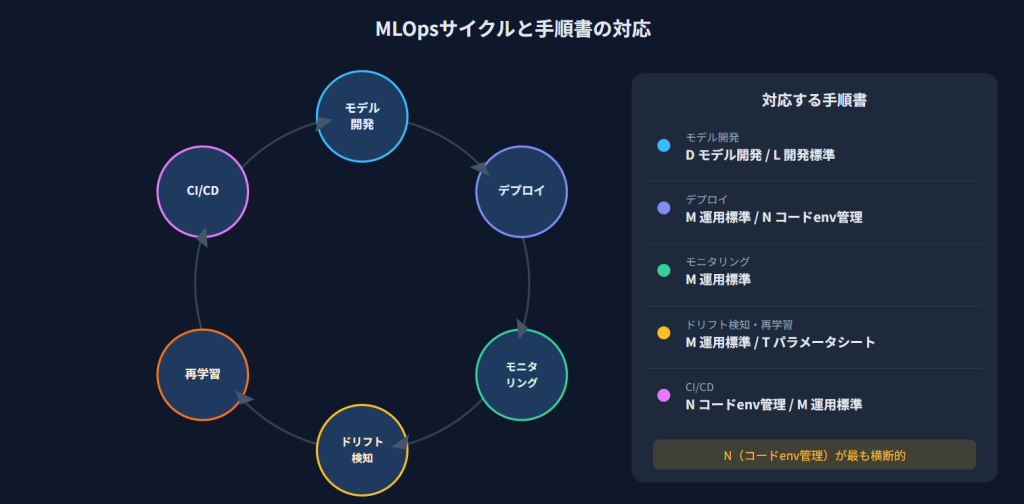
MLOpsとは、モデルの開発と運用を切り離さず、ひとつのサイクルとして回し続ける考え方だ。たとえば客数予測のように天候やイベントの影響を受けるモデルでは、一度作って終わりにはならない。
モデル開発 → デプロイ → モニタリング → ドリフト検知 → 再学習 → 再デプロイ
このサイクルの各ステップが、そのまま手順書に対応する。
| MLOpsサイクル | 対応する手順書 | やること |
|---|---|---|
| モデル開発 | D(モデル開発), L(開発標準) | 特徴量設計・学習・評価・チューニング |
| デプロイ | M(運用標準), N(コードenv管理) | dev→prod昇格・API Deployer・ライブラリ反映 |
| モニタリング | M(運用標準) | ドリフト検知・精度指標の定期確認 |
| 再学習トリガー | M(運用標準), T(パラメータシート) | 閾値を超えたときの再トレーニング自動実行 |
| CI/CD | N(コードenv管理), M(運用標準) | モデルバージョニング・検証・自動デプロイ |
「どの手順書を、いつ、誰が見るか」が決まっていれば、MLOpsは特定の人に依存せず、チームの仕組みとして回る。ドキュメント設計は単なる文書管理ではなく、MLOpsを組織に根づかせるための土台でもある。
まとめ
Dataikuプロジェクトでドキュメントを設計するときに押さえておきたいポイントを並べる。
- 利用者を5ロールに分けてから設計する。 ロールが曖昧なまま書き始めると、誰向けかわからない手順書が量産される。
- 業務チーム向けにはDataikuの用語を出さない。 彼らの関心はアプリの操作結果であって、プラットフォームの仕組みではない。
- 共通手順書+パラメータシートで標準化する。 プロジェクトが増えてもパラメータシートを足すだけで対応できる。
- 「作る手順書」と「使う手順書」は分ける。 読む人が違うものを1本にまとめると、どちらにとっても使いにくくなる。
- Pythonライブラリ管理は独立した手順書にする。 dev/prodをまたぐ話は他の手順書と混ぜると収拾がつかなくなる。
- ライフサイクルのどのフェーズで使うかを明示する。 「いつ開くか」がわからない手順書は読まれない。
- 手順書構成をMLOpsサイクルに対応させる。 ドキュメントの構造がそのまま運用の構造になる。
設計の方針を持って整理すれば、手順書の本数もメンテナンスコストも抑えられる。これからDataikuを導入するチームにとって、何かしら参考になれば幸いだ。

コメントを残す